One day I was innocently browsing around a GIS data page and realized, “Wow, there’s so much open data here, I wonder what I could do with it if I were able to collect it all?” This is both a journey through my learning process of mining data, using Selenium (which I didn’t even know existed), as well as my process of figuring out exactly how the data is organized such that I could mine it. I’ll finish by taking you through how to appropriately organize and present that data in such a way that an average person can understand what they are looking at.
Table of Contents
GIS Data
There are some counties that openly allow full download (zip file typically) of GIS (Global Information Survey) property data. For all I know, I could have simply asked for the data and it would have been provided. What I was really after was learning how to use tools such as Selenium and Python to acquire datasets online. After interacting via email with a GIS data admin for my county, I was able to get a general idea how plats were organized and how to loop through the data. My notes are below:
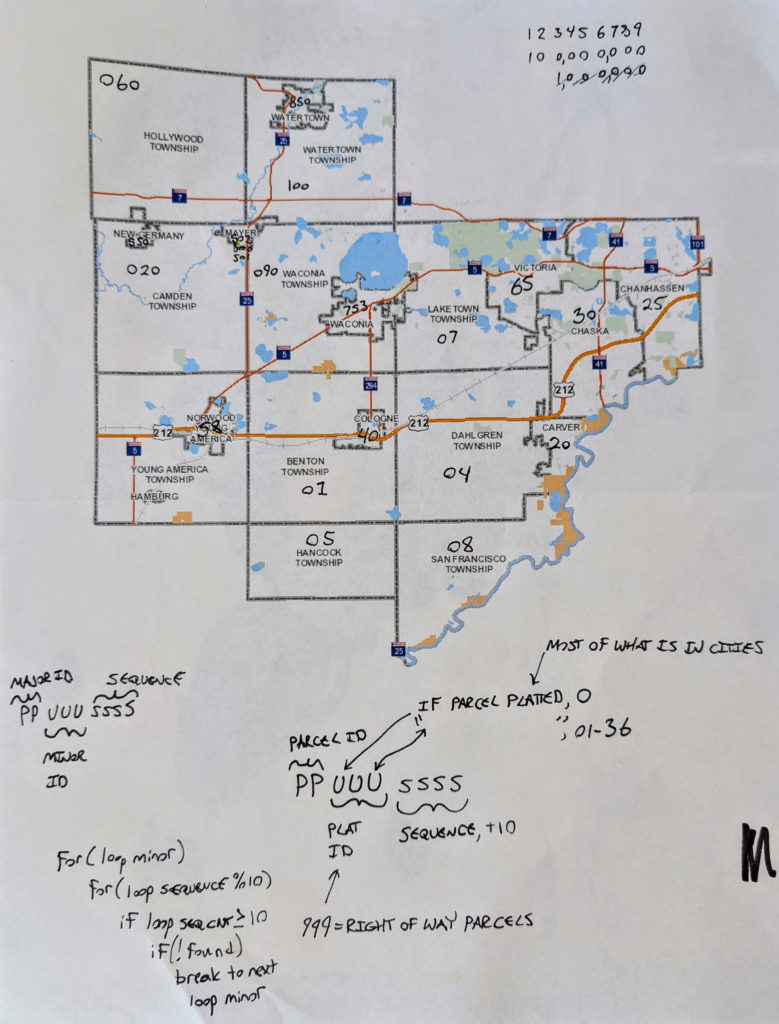
It is quite incredible how complex plats are in that they aren’t sequential, nor are townships or any form of housing blocks. I really had to understand what regions of the ID to loop over, what to increment by (typically by 10), and how the data was organized. After some trial and error, I realized the quickest way to collect this data (there are tens and tens of millions of ID’s, most of which are invalid) is to first figure out which ID’s had data, and which didn’t. To do that I turned to the source code of the site exposing the data and realized they had JavaScript I could utilize. I noticed that in the file, ccSearch.js, there was a function called performPlatNumSearch() which took a plat ID in the form of a string which would either return an element named platSpan_1 or nothing. With that information combined with the knowledge above of how to generate plats I will now detail the script I created which collected valid plats.
Selenium
There are plenty of great tutorials on how to setup Selenium, one I found helpful was this tutorial. I use linux, so my setup may be different than yours, however, I used Chrome as my webdriver. I also setup headless as I don’t care to see the resulting webpage, and I also had to enable javascript so I could call the performPlatNumSearch() script. Throughout these tutorials, I am using pandas extensively to organize the data as it is collected.
import pandas as pd
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from multiprocessing import Process
from multiprocessing import Pool
import time
Major IDs
Through some quick browsing around the various towns within Carver County I was able to generate a list of “Major ID’s”, drastically narrowing down the range of IDs I needed to check. I then created a static array which I could loop through.
plat_majors = [6, 85, 10, 55, 2, 50, 9, 75, 7, 65, 30, 25, 20, 4, 40, 1, 58, 5, 8]
Plat Search
Next was the actual function which would take the known Major IDs and loop through them, creating a csv file with all the valid plat IDs from each Major ID set. Again, this function utilizes Selenium to open a webpage and execute a javascript on that page. A plat string is generated based on the passed in major id, combined with the looped over minor id. It then attempts to find an element by id called “platSpan_1” which indicates there is a valid plat. If successful, the plat id(s) are collected in a pandas dataframe which is ultimately saved to a csv file. If it can’t, an exception occurs which is handled and a “not found” message is printed.
def platSearch(parcel_major):
df = pd.DataFrame(columns=['Plat_ID'])
df.head()
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--enable-javascript')
driver = webdriver.Chrome(executable_path='/usr/bin/chromedriver', options=chrome_options)
filename = 'PlatIDs_' + str("{0:02}".format(parcel_major)) + '.csv'
for minor in range(0, 999):
platid_str = str("{0:05}".format((parcel_major * 1000) + minor))
url = 'https://gis.co.carver.mn.us/platsearch/'
driver.get(url)
content = driver.page_source
scripttxt = 'performPlatNumSearch("' + platid_str + '","")'
driver.execute_script(scripttxt)
time.sleep(1)
try:
elem = driver.find_element_by_id('platSpan_1')
except NoSuchElementException:
print(platid_str + " not found")
else:
print(platid_str + " found!")
for option in elem.find_elements_by_tag_name('option'):
df = df.append({'Plat_ID': option.get_attribute("value")}, ignore_index=True)
df.to_csv(filename, index=False, encoding='utf-8')
driver.close()
Python Parallelism
One last step was to call the platSearch() function. Because it had a time.sleep(), I decided to parallelize this task across the Major IDs to speed up the data collection. I used python’s multiprocessing to do this which spawns a new process for each ID as follows:
if __name__ == "__main__":
task = []
for maj in plat_majors:
p = Process(target=platSearch, args=(maj,))
task.append(p)
p.start()
Next Step: Data Collection
In Part two of this series, I will cover how I use the newly discovered list of valid plats to mine data for each plat, and create a big set of data that I can use to glean interesting information from.